


We've been waiting for these thinking machines for a long time now. We've read about them, and seen them in countless movies. They are just technology, right? And we've gotten really good at this technology thing! But where are the machines?
In a previous post I've hinted at the big problem in serious Artificial Intelligence (AI) research: if the theory of consciousness based on the concept of integrated information is right, then thinking machines are essentially undesignable.
Mind you, we do have smart machines. We have machines that outperform humans in playing chess, we have self-driving cars that process close to 1Gbit per second of data, and we have machines that can beat pretty much anybody at Jeopardy! But neither you, or I, would call these smart machines intelligent. We do not take that word lightly: if you're just good at doing one particular job, then you're smart at that, but you are not intelligent. Google's car cannot play chess (nor can Watson), and neither Big Blue nor Watson should be allowed behind the wheel of a car.
What's going on here?
Here's the most important thing you need to know about what it takes to be intelligent. You have to be able to create worlds inside your brain. Literally. You have to be able to imagine worlds, and you have to be able to examine these worlds. Walk around in them, linger.
This is important because you live in this world, the one you are also imagining. This world is complex, it is dangerous, and it is often unpredictable. It is precisely this unpredictability that is dangerous: you can be lunch if you don't understand the tell-tale signs of the lurking tiger.
Yes I know, your chances of being eaten by a tiger are fairly low, but I'm not talking about today: I'm talking about the time when we (as a species) "grew up", that is, when we came down from the trees and ventured into the open fields of the savannah. To survive in this world, we have to make accurate predictions about the future state of the world. (Not just in the next five minutes, but also on the scale of months, seasons, years.)
How do we make these predictions? Why, we imagine the world, and in our minds imagine what happens. These imaginings, juxtaposed with the things that really do happen, allow us to hone a very important skill: we can represent an abstract version of the world in our heads, and use it to understand it. Understanding means removing surprises, the things that usually kill you.
Thinking about an object thus means creating an abstract representation of this object in your head, and playing around with it. If you can't do that, then you cannot think. You cannot be intelligent.
Are workers in the field of Artificial Intelligence oblivious about this absolutely crucial, essential aspect of intelligence?
Absolutely not. They are perfectly aware of it. In the heydays of AI research, that's pretty much all people did: they tried to cram as many facts about the real world into a computer's memory as they could. This, by the way, is still pretty much the way Watson is programmed, but he has a smarter retrieval system than what was possible in those days, based on Bayesian inference.
But in the end, the programmers had to give up. No matter how much information they crammed into these brains, this information was not integrated: it did not produce an impression of the object that allowed the machine to make new inferences about the object that were not already programmed in. But that is precisely what is needed: your model of the world has to be good enough so that (when thinking about it) you can make predictions about things you didn't already know.
So what did AI researchers do? Some gave up, and left the field. Others decided that they could do without these pesky imagined worlds. That you could create intelligence without representation. (The linked article is available beyond the paywall all over the internet, for example here. Tells you something about paywalls.) NOTE: This was available until recently! Also tells you something about paywalls.
Given all that I just told you, you ought to at least be baffled. It all seemed so convincing! You can do without internal models? How?
The idea that you could do away with representations for the purpose of Artificial Intelligence is due to Rodney Brooks, then Professor of Robotics at MIT. Brooks is no slouch, mind you. His work has influenced a generation of roboticists. But he decided that robots should not make plans, because, well, the best laid plans, you know....
Rather Brooks argued that robots should react to the world. The world already contains all the complexity! Why not use that? Why program something that you have direct access to?
Why indeed? Brooks was quite successful with this approach, creating reactive robots with a subsumption architecture. Reactive robots are indeed robust: they can act appropriately given the current state of the world, because they take the world seriously: the world is all they have.
But I think we can all agree that these robots, agile as they are, won't ever be intelligent. They won't be able to make plans. Because plans require good internal models, which we don't know how to program.
So where will our intelligent machines come from?
The avid reader of Spherical Harmonics (should such a person actually exist), already knows the answer to this question. Evolution is the tool to create the undesignable! If you can't program it, evolve it! After all, that's where we came from.
Now, I've hinted at this before: evolve it! Can you actually evolve representations?
Yeah, we can, and we've shown it. And there is a paper that just came out in the journal Neural Computation that documents it. That's right, you've been reading a blog post that is an advertisement for a journal article that is behind a pay wall!
Relax, there is a version of the article on the AdamiLab web site. Or go get it from arxiv.org here.
Now back to the specifics: "You've evolved representations, you say? Prove it!"
Ah! Now, a can of worms opens. How can you show that any evolved anything actually represents the world inside its.... bits? What are representations anyway? Can you measure them?
Now here's a good question. It's the question the empiricist asks, when he is entangled in a philosophical discussion. And lo and behold, the concept of representation is a big one in the field of philosophy. Countless articles have been written about it. I'm not going to review them here. I have this sneaking suspicion that I am, again, engaged in writing an overly long blog post. If you're into this sort of thing (reading about philosophy, as opposed to writing overly long blog posts), you can read about philosophers talking about representation here, for example. Or here. I could go on.
Philosophers have defined "representation" as something that "stands in" for the real thing. Something we would call a model. So we're all on the same wavelength here. But can you measure it? What we have done in the article I'm blogging about, is to propose an information-theoretic measure for how much a brain represents. And then we evolve a brain that must represent to win, and measure that thing we call representation. But then we go one better: we also measure what it is that these brains represent.
We literally measure what these brains are thinking about when they make their predictions.
How do we do that? So, first of all, we understand that when you represent something, then this something must be information. Your model of the world is a compressed representation of the world, compressed into the essential bits only. But importantly, you're not allowed to get those bits from looking at the world. Staring at it, if you will. If you have a model of the world, you can have that model with your eyes closed. And ears. All sensors. Because if you could not, you would just be a reactive machine. So, a representation is those bits of the worlds that you can't see in your sensors. Can you measure that?
Hell yes! Claude Shannon, that genius of geniuses, taught us how! Here is the informational Venn diagram between the world (W), the sensors (S) that see the world (they represent it, albeit in a trivial manner), and the Brain (B):
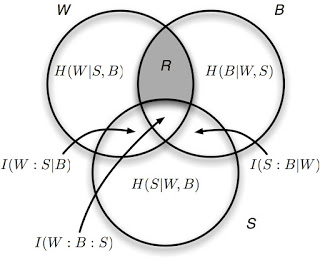
What we call "representation" (R) is the information that the brain knows about the world (information shared between W and B) given the sensor states (S). "Given", in the language of information theory, means that these states (the sensor states) do not contribute to your uncertainty. It also means that the "given" states do not contribute to the information (shared entropy) between W and B. That's why the "intersection triangle" between W, B, and S does not contribute to R: we have to subtract it because it also belongs to S. (I will talk about these concepts in more detail in part 2 of my "What is Information? series) So, R is what the brain knows about the world without sneaking a peek at what the world currently looks like in the sensors. It is what you truly know.
Now that we have defined representation quantitatively (so that we can measure it), how does it evolve?
Splendidly, as you may have surmised. To test this, we designed a task (that a simulated agent must solve) that requires building a model of the task, in your brain. This task is relatively simple: you are a machine that catches blocks. Blocks rain down from the sky (falling diagonally) but there are two kinds of blocks in the world. Small ones (that you should definitely catch) and large ones (that you should definitely avoid). To make things interesting, your vision is kind of shoddy. You have a blind spot in the middle of your retina, so that a big block may look like a small bock (and vice versa), for a while.
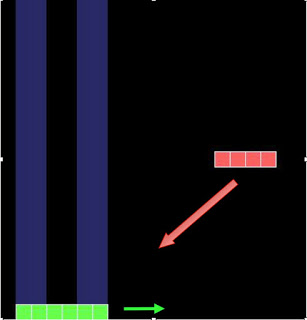
In this image, a large block is falling diagonally to the left. This is a tough nut to crack for our agent, because he hasn't even seen it. He is moving in the right direction (perhaps by chance) but once the block appears in the agent's sensors, he has to make a decision quickly. You have to determine both size, direction of motion, and relative location (is the block to my left? right above me? to my right?) You have to integrate several informational streams in order to "recognize" what you are dealing with. And the agent'a actions will tell us whether he has "understood" what it is what he is dealing with. That's what makes this task cool.
We can in fact evolve agents that solve this task perfectly, that is, they determine the right move for each of the 80 possible scenarios. Why 80? Well the falling block can be in 20 different positions at the top row. It can be small or large. It can fall to the left or to the right: 20 x 2 x 2 = 80. You say that I'm neglecting the 20 possible relative positions of the catcher? No I'm not: because the game "wraps" in the horizontal direction. Then if the block falls off the screen from the left, it reappears, as if by magic, on the left. The agent also reappears on the left/right if he disappears on the right/left. As a consequence, we only have to count the 20 relative positions between falling block and catching agent.
As the agents become more proficient at catching (and avoiding) blocks, our measure R increases steadily. But not only can we measure how much of this world is represented in the agent's brain, we can literally figure out what they are thinking about!
 If any of our information theory is correct, it is just a matter of technology to get the kind of data that will provide answers to these questions. That technology is far from trivial. In order to determine what we know about the brains that we evolve, we have to have the time series of neuronal firing (000010100010 etc) for all neurons, for a considerable amount of time (such as, the entire history of experiencing all 80 experimental conditions). That's fine for our simple little world, but it not at all OK for any realistic system. Obtaining this type of resolution for animals is almost completely unheard of. Daniel Wagenaar (formerly at Caltech and now at the University of Cincinnati) can do this for 400 neurons in the ganglion of the medicinal leech. Yes, the thing seen on the left. Don't judge, it has very big neurons!
If any of our information theory is correct, it is just a matter of technology to get the kind of data that will provide answers to these questions. That technology is far from trivial. In order to determine what we know about the brains that we evolve, we have to have the time series of neuronal firing (000010100010 etc) for all neurons, for a considerable amount of time (such as, the entire history of experiencing all 80 experimental conditions). That's fine for our simple little world, but it not at all OK for any realistic system. Obtaining this type of resolution for animals is almost completely unheard of. Daniel Wagenaar (formerly at Caltech and now at the University of Cincinnati) can do this for 400 neurons in the ganglion of the medicinal leech. Yes, the thing seen on the left. Don't judge, it has very big neurons!
Article reference: L. Marstaller, A. Hintze, and C. Adami. (2013). The evolution of representation is simple cognitive networks. Neural Computation 25:2079-2107.
We can in fact evolve agents that solve this task perfectly, that is, they determine the right move for each of the 80 possible scenarios. Why 80? Well the falling block can be in 20 different positions at the top row. It can be small or large. It can fall to the left or to the right: 20 x 2 x 2 = 80. You say that I'm neglecting the 20 possible relative positions of the catcher? No I'm not: because the game "wraps" in the horizontal direction. Then if the block falls off the screen from the left, it reappears, as if by magic, on the left. The agent also reappears on the left/right if he disappears on the right/left. As a consequence, we only have to count the 20 relative positions between falling block and catching agent.
As the agents become more proficient at catching (and avoiding) blocks, our measure R increases steadily. But not only can we measure how much of this world is represented in the agent's brain, we can literally figure out what they are thinking about!
Is this magic?
Not at all, it is information theory. The way we do this, is by defining a few (binary) concepts that we think may be important for the agent, such as:
Is the block to my left or to my right?
Is the block moving left or right?
Is the block currently triggering one of my sensors?
Is the block large or small?
Granted, the world itself can be in 1,600 different possible states. (Yes, we counted). These 4 concepts only cover two to the power of 4, or 16 possible states. But we believe that the agent may want to think about these four concepts in order to come to a decision; that these are essential concepts in this task.
Of course, we may be wrong.
But we can measure which of the twelve neurons encode each of the four concepts, and we can even determine the time when they have become adapted to this feature. So, do the agents pay attention to these four concepts as they learn how to make a living in this world?
Not exactly, actually. That would be too simple. These concepts are important to a bunch of neurons, to be sure. But it is not like a single neuron evolves to pay attention to "big or small" while another tells the agent whether the brick is moving left or right. Rather, these concepts are "smeared" across a bunch of neurons, and there is synergy between concepts. Synergy means that if two (or more) neurons are encoding a concept together synergistically, then together they have more information about it then summing up the information that each one has by itself.
So what does all of this teach us?
It means (and of course I'm biased here), that we have learned a great deal about representation here. We can measure how much a brain represents about its world within its states information-theoretically, and we can (with some astute guessing) even spy on what concepts the brain uses to make decisions. We can even see these concepts form as the brain is processing the information. At the first time step, the brain is pretty much clueless: what it sees can lead to anything. After the second time step, it can rule out a bunch of different scenarios, and as time goes by, the idea of what the agent is looking at forms. It is a hazy picture at first, for sure. But as more and more information is integrated, the point in time arrives where the agent's mental image is crystal clear: THIS is what I'm dealing with, and this is why I move THAT way.
It is but a small step, for sure. Do brains really work like this? Can we measure representation in real biological brains? Figure out what an organism thinks about, and how decisions are made?
If any of our information theory is correct, it is just a matter of technology to get the kind of data that will provide answers to these questions. That technology is far from trivial. In order to determine what we know about the brains that we evolve, we have to have the time series of neuronal firing (000010100010 etc) for all neurons, for a considerable amount of time (such as, the entire history of experiencing all 80 experimental conditions). That's fine for our simple little world, but it not at all OK for any realistic system. Obtaining this type of resolution for animals is almost completely unheard of. Daniel Wagenaar (formerly at Caltech and now at the University of Cincinnati) can do this for 400 neurons in the ganglion of the medicinal leech. Yes, the thing seen on the left. Don't judge, it has very big neurons!
And, we are hoping to use Daniel's data to peer into the leech's brain, see what it is thinking about. We expect that food and mating are the variables we find. Not very original, I know. But wouldn't that be a new world? Not only can we measure how much a brain represents, we can also see what it is representing! As long as we have any idea about what the concepts could be that the animals are thinking about, that is.
I do understand, from watching current politics, that this may be impossible for humans. But yet, we are undeterred!
Article reference: L. Marstaller, A. Hintze, and C. Adami. (2013). The evolution of representation is simple cognitive networks. Neural Computation 25:2079-2107.
